E. Dentro del laboratorio: SPEAK 3.0 / 3.1
El siguiente texto ha sido elaborado, en su especificidad, por Fabián Kesler, integrante del proyecto; y reelaborado por Alejandra Ceriani para su presentación en este Anexo [“Speak 3.0 - Dentro del laboratorio. Escrito 1: El dispositivo de video”. De Alejandra Ceriani, Fabricio Costa Alicedo y Fabián Kesler. Documento bajo licencia de Creative Commons. Se puede citar, copiar y utilizar por fuera de su sitio web dando aviso a los autores.
Hablamos primordialmente de renunciar a los pre-conceptos rígidos sobre “músico, “videasta”, “bailarina”; en pos de lo multimedial, de estar realmente al tanto de lo que cada uno de nosotros está generando y, de este modo, tener un mayor panorama respecto de relacionar movimiento, imagen y sonido. Intentamos echar luz sobre algunos de los procedimientos técnicos que alimentaron la creación conceptual y poética de nuestra obra Speak 3.0.
E.1 Acerca de los parámetros de captación de la cámara web
A continuación vamos a exponer las especificaciones técnicas sobre la tercera etapa de esta obra.
Speak tiene como uno de sus ejes conceptuales y prácticos la captación de un cuerpo humano por el sensado de una cámara, y la posterior utilización estética y poética de los datos que esta genera. Los modos y los parámetros de captación han ido variando a través de las diferentes versiones de Speak.
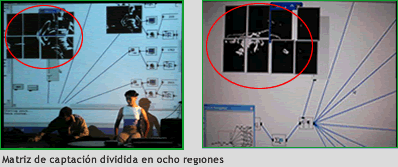
En Speak se trataba de una matriz de captación dividida en ocho regiones
,en las cuales el cuerpo y la imagen del cuerpo, podían entrar y salir (bajo las mismas condiciones ya desarrolladas para PROYECTO HOSEO), generando tanto emisión sonora como procesamiento dentro de las diferentes regiones, “concertando” a entrar en un diálogo multimedial.
VER VIDEO
Aquí el cuerpo del performer era un instrumento que generaba sonido. El cuerpo se movía o no componiendo silencios o sonidos, a la par que concertaba con otros en un espacio sonoro inmersivo.
En Speak 2.1, la pantalla –dividida en dieciséis zonas– captaba las señales lumínicas, en lugar de un cuerpo, para transformarse en sonido.
El concierto pasa a ser menos antropomórfico. Los cuerpos se iconizan en trazos de luz, los roles de la ‘bailarina’ y del ‘músico’ se mixturan. Se vitaliza la figura del gesto corporal, del gesto expresivo en pos de una micro danza. El performer interactivo y el músico manipulan un dispositivo de interfaz analógico, una linterna láser. El punto de luz va entrando en las regiones, donde cada una tiene asignado un sonido diferente en la programación del MAX.
VER VIDEO
El interés de esta propuesta interactiva radicaba en comprometer la inter-actuación escénica del cuerpo del músico programador. Un concierto interactivo: movimiento y sonido desde el gesto corporal compartido.

Explicaremos a continuación el dispositivo visual de Speak 3.0, donde se utiliza el software MOLDEO, creación de Fabricio Costa Alisedo. Además de tomar algunos conceptos de las versiones anteriores, Speak 3.0 ofrece nuevas maneras de inter-relacionar y pensar la música, el movimiento, la imagen y la composición simultánea de los tres medios.
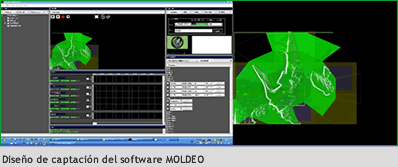
Respecto del uso de la cámara como sensor, en Speak 3.1 (2010), se trata de una cámara de vigilancia infrarroja (SAMSUNG SHC 735- IR) colocada de modo frontal a 45º en relación con el plano frontal del performer.
VER VIDEO
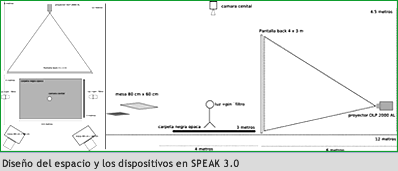
Esta actual modalidad de la disposición espacial de los elementos usados en la puesta interactiva nos trajo otros cambios a nivel escénico, cambios a nivel del diseño de la imagen proyectada por MOLDEO y de los movimientos de interacción realizados por el performer. Las luces de leds infrarrojas, más la cámara que capta, permiten dejar a oscuras el espacio y el cuerpo del performer, dando como resultado un cuerpo-silueta interactuando en la oscuridad.


E.2 La captación de la silueta
Para Speak 3.0, la cámara se dispone de manera cenital. Esto permite un buen seguimiento de los movimientos del performer en la zona de espacio determinado por la lente de la cámara. La programación en su conjunto está diseñada para interactuar con la cámara como sensor, el software Moldeo y las interfaces físicas y virtuales.
Entre los objetos utilizados dentro de la programación de Moldeo destacaremos los siguientes elementos:
a- Baricentro:
Es un punto X - Y (bidimensional). Es la ubicación espacial promedio de todos los puntos de “trackeo” (seguimiento de una silueta detectada). Por lo tanto, la zona de mayor densidad de puntos detectados en una silueta es análoga al centro de gravedad de un objeto.

VER VIDEO
Podemos disponer de varias siluetas detectadas, o de varias zonas del cuerpo independizadas, y así tener varios baricentros. Esto aumenta las posibilidades de contrapuntos y juegos de los elementos visuales entre sí, y también, con el sonido y el movimiento.
Cabe aclarar que el baricentro ideal sería exactamente el centro de la silueta, pero si en el espacio hay irregularidades, como reflejos u objetos captados (“ruido” que llega a la cámara), dicho baricentro se puede desplazar. El mínimo baricentro es x0-y0 (origen) y el máximo x1-y1 (extremo en diagonal al origen). El software Moldeo trabaja con un campo entero y seis decimales.
b- Varianza:
Es la suma de todas las desviaciones de la silueta tomando como referencia su baricentro. Es decir, cuánto varía la posición del cuerpo captado respecto a una posición de referencia.
La varianza puede ser sobre el eje X (horizontal) y/o sobre el eje Y (vertical) que capta la cámara cenitalmente. Por ejemplo, un cuerpo recogido generará mínima varianza, mientras que si se extienden los brazos tendremos un valor alto de varianza.
En la segunda versión de Speak 3.0, la varianza está asignada a la aparición de sonidos.
VER VIDEO
Es decir, que en el momento donde el performer expande sus brazos genera una variación en el volumen y, además, procesa (pitch, envolventes, etc.) los sonidos según dicha varianza sea vertical u horizontal.

La varianza da la idea de cómo están distribuidos los puntos detectados: si muy juntos (mayor densidad) o muy separados (menor densidad), y todos los estados intermedios.
Matemáticamente, se representa la varianza como un vector (un direccionamiento) X (horizontal) y otro Y (vertical), ambos, con origen cero en el baricentro, se extienden hasta la densidad de puntos captados.
La medida entre el punto origen y la zona espacial más lejana de las desviaciones (ambos puntos son un promedio) nos da la varianza.
E.3 Acerca de la matriz de posición
Si la persona captada estira los brazos en sentido vertical para la visión de la cámara cenital, tenemos alta varianza vertical; si los dispone en diagonal, la varianza se reparte en ambos ejes.

Para que esta medición sea en 3D –es decir, agregar la profundidad (eje z)–, solo es necesario utilizar una cámara extra, lateral a la silueta. Un tercer campo de varianza ofrece el vector del largo de la hipotenusa (raíz cuadrada de X al cuadrado + Y al cuadrado, teorema de Pitágoras). Siempre es positivo y su valor máximo es raíz cuadrada de 2, pues:
Max X=1
Max Y=1.
Tenemos mínimo cero y máximo uno para medir la magnitud de las varianzas, o sea el largo de los vectores. Con el baricentro y la varianza obtengo la posición promedio X-Y de la silueta en el espacio medido. Recordemos que es un vector (una medida desde el origen en cierta dirección) y no un segmento (dos puntos cualesquiera en el espacio).
Se entiende que la mínima varianza corresponde a 0-0, y la máxima varianza posible a 1-1, dada por el tamaño de cuadro de la cámara utilizada.
La varianza –junto al baricentro– otorga a modo estadístico más datos a ser aprovechados artísticamente:
- Cuánto espacio físico ocupa la silueta.
- Su posición espacial.
En Moldeo se establece un máximo de puntos a utilizar que por defecto lo ajustamos en 100 (n=100). También se puede establecer un mínimo de puntos, y por medio de un condicional, establecer que debajo de cierta cantidad de puntos, lo que detecta la cámara es ruido, es decir, elementos del ambiente o reflejos que no nos interesan, y por lo tanto son ignorados.
E.4 Acerca de la matriz de posición
La matriz de posición que se utiliza en Speak 3.0 puede transformarse de manera dinámica. En algunos momentos de la obra se utiliza una matriz cuadrada de dieciséis zonas de captación independientes, similar a la utilizada en Speak 2.0, pero con otros usos tanto técnicos como estéticos.
Una elección estética que hacemos de esta distribución es sensibilizar las cuatro zonas extremas. En cuanto el performer entra en alguna de esas zonas, se generan procesos de modificación en el sonido.
Es decir, que a nivel de movimiento el cuerpo se mueve con relación a la masa=inercia, cuantificando la cantidad de píxeles que entra en las zonas angulares. La velocidad de traslado de un ángulo a otro incide en el volumen y en la duración del procesamiento del sonido a través de la manutención de la masa de píxeles. Antes de que se desvanezca se vuelve a entrar a esa zona. Esto hace que los recorridos entre las zonas sean vertiginosos e incesantes. Si se quisiera sostener un sonido llevándolo al máximo de su des-configuración a través de los distintos procesamientos, el cuerpo del performer –considerado masa de píxeles– deberá permanecer moviéndose en cada zona por más tiempo. De este modo, la composición sonora que genera el performer tiene que ver con los desplazamientos en diferentes velocidades, las detenciones momentáneas y/o las permanencias activas.
VER VIDEO
La imagen, por su parte, indica estas interacciones y modificaciones sobre lo sonoro, señalando colores y figuras diferentes al entrar en los ángulos del encuadre de la cámara y de la matriz de la programación.
E.5 Acerca de la velocidad y la aceleración
Los datos de velocidad de movimiento de la silueta también son generados y aprovechados tanto con fines visuales como sonoros.
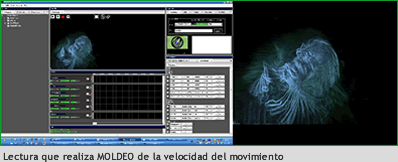
Tenemos tres campos:
1: el vector: velocidad de la normal. El largo de la hipotenusa (raíz cuadrada de X al cuadrado + Y al cuadrado, teorema de Pitágoras). Siempre es positivo.
2: velocidad en el eje X
3: velocidad en el eje Y
Valor 64= capta al objeto, pero está quieto.
Valor 0= no existe el objeto, no es captado.
Tomando algunos conceptos físicos simples, podemos generar movimientos con detención (rectos con cambio de dirección), movimientos continuos (circulares), etcétera. Se dispone de la información por cada una de las dieciséis regiones:
VER VIDEO
Matriz de movimiento: medición del movimiento en cada una de las regiones. Se “traquea” la velocidad. Puede haber casos de detección de posición y no de movimiento; por ejemplo, objetos estáticos de la sala.
Matriz de aceleración: capta la aceleración en cada una de las dieciséis regiones. Puede haber captación de velocidad en algunas regiones, pero no de aceleración si la velocidad es constante, y de manera diferente en otra zona.
Ejemplo: en un momento se miden dos puntos en movimiento y tres en aceleración. Eso implica que un punto se detuvo (aceleración negativa).
E.6 Acerca de la matriz de posición (mp)
La matriz de posición que se utiliza en Speak 3.0 se puede transformar de manera dinámica. En algunos momentos de la obra utilizamos una matriz cuadrada de dieciséis zonas de captación independientes, similar a la utilizada en Speak 2.0, pero con otros usos tanto técnicos como estéticos. MOLDEO detecta e informa la cantidad de puntos que corresponden a cada una de las dieciséis zonas de la matriz, es decir, cómo se distribuye la totalidad de puntos captados (campo “n” en moldeo).

Una utilización estética que realizamos de esta matriz cuadrangular es sensibilizar las cuatro zonas extremas. En cuanto el performer entra en alguna de esas cuatro zonas, se generan procesos en el sonido. A más puntos en la zona, el efecto es más notorio.

VER VIDEO
Para Speak 3.1 (2010) las zonas se han marcado como franjas verticales, justamente por la posición de la captación de la cámara: frontal y a 45º.
VER VIDEO
